According to the Society of American Archivists, web archiving is…
the process of collecting, preserving, and providing enduring access to web content
Dictionary, Society of American Archivists
So why archive webpages?

Personal websites, digital portfolios, and digital humanities projects in particular are prone to dying. Since these projects may sometimes be one-off assignments for a course or digital work completed by students with more limited resources than gigantic institutions, they often fall prey to the pit of defunctness. Archiving a copy of web-based or web-hosted projects before you officially decide to step away from them is the best way to preserve your work, either for future self-reflection or for other scholars/users who may find it crucial to their own workflows or research.
What is web archiving good for?
Note that if you’re looking to archive webpages just so that you can see an earlier version of your site, there are much better ways to do that using version control systems like Git or Mercurial. Web archiving is most useful for saving an accessible copy of webpages and websites that are not likely to be repeatedly crawled or are not already part of a dedicated archiving program. At Cornell, for example, archiving a cornell.edu site is a moot point, since Cornell University Library’s Web Archiving Technician crawls all cornell.edu sites on a schedule using an institutional instance of the Internet Archives’ paid ArchiveIt service. Archiving my personal website, my favourite blog post, or an obscure digitized copy of a crucial 19th-century text would be a great use of web archiving, since these sites and pages may not be captured by someone else’s proprietary or institutional crawler.
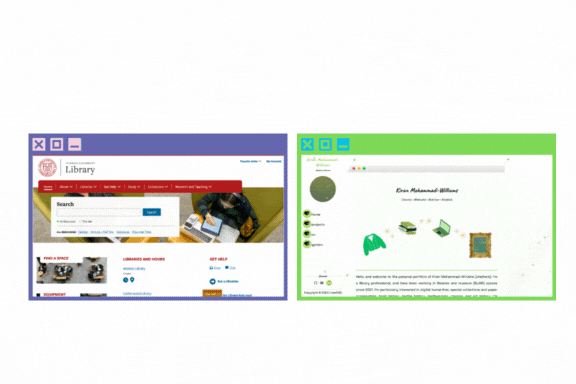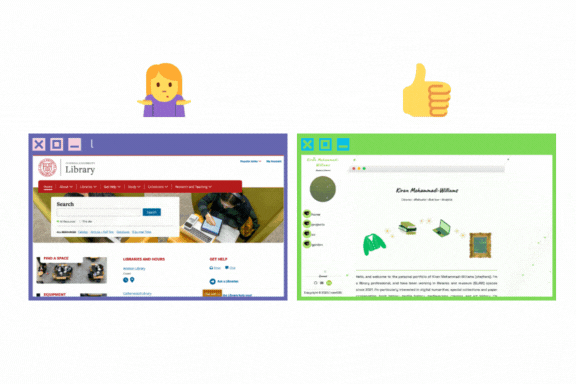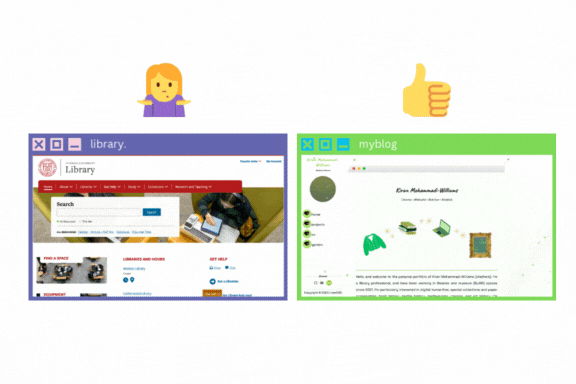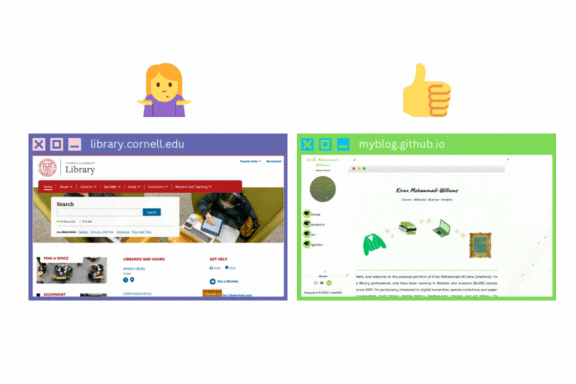
Getting started
Terms to know
ArchiveIt has a glossary of terms that may be useful to review, but the main five that will come up in this guide are: snapshot, capture, WARC file, website, and webpage. You may be thinking that website and webpage are self-explanatory terms, but it’s important to know the difference since some web archiving tools will only capture pages, while others will capture entire websites.
- Capture: A full copy of the digital information encoded within a webpage or website that is then archived.
- Snapshot: A complete capture of a website or webpage’s content at a specific point in time. As if you had taken a screenshot of the page, but interactive.
- WARC file: A web archive file format that contains a capture of a specific URL.
- Website: A collection of web resources and pages hosted in one particular place and hosted on the Internet by a web server.
- webpage: A single HTML-based document on the web, often hosted on a website through a relative URL (e.g. website.com/web-page/).
Types of web-archiving tools
Before you can get started with archiving a page or a site, it’s important to know what kinds of tools exist. While there are dozens of tools out there, most of them can be categorized using a few basic types: self-hosted and service-hosted; one-page or full-site; and/or open-source and closed-source.
Self-hosted and service-hosted
Whenever something goes on the Internet, it needs to be hosted and served by a web server of some sort. You can read more about the basics of web servers on our guides site. What this means is that when you make your capture of the site or page you want to archive, you’ll have to store that capture somewhere and use some sort of web service to view it.
Self-stored and self-hosted web archiving tools allow you to create a WARC file that you can store on your computer, which you can then serve to your computer’s local server (which is not connected to the Internet) or view through a browser-based WARC viewer like WebRecorder’s Replay Webpage. The file stays on your computer and is fundamentally controlled and owned by you, but you can use a variety of methods to view the archived page or site.
Service-hosted web archiving tools are full-service pieces of web-based software, meaning all you have to do is make an account, pop in URLs for web sites and pages that you’d like to preserve, and wait for the software to process them. Service-hosted archiving tools often have built-in viewers, let you add captures to specific collections, and have graphical user interfaces (visual interfaces you can interact with in your browser) for accessing, adding, viewing, and editing captures.
So which one should you use? There are many pros and cons to both self-managed and service-managed web archives, so the decision you make can be informed by those positive and negatives. Here are just a few:
Self-hosted
- Storage limits dependent on your computer and external harddrives (way beyond 5G)
- Full control over the archived page
- Can experiment with code of archived page
- Relatively stable copy of page DOM
- Accessible on the fly
- Can view on local server or choose own viewer
Service-hosted
- Almost no work
- Easily accessible
- Viewer built into the platform
- Links are easily sharable with others
- Can download WARC and WACZ if needed
- PDF or png conversion of snapshot
- Automated provenance summaries
Self-hosted
- High upfront investment of time and energy
- Might need an external viewer
- Requires technical knowledge (command line, programming languages)
Service-hosted
- Upload limits
- Sometimes paid features
- Snapshots on proprietary servers (companies go out of business)
- Storage limits
- No access if the service/tool server goes down
If you’re just archiving individual webpages that are useful for your research or personal endeavours, then a service-hosted archive on an open-source platform may be your best option. While we can’t guarantee that even big service-hosted options like Internet Archive’s Wayback Machine will remain available forever, there’s a decent likelihood of their long-term stability given current institutional support.
One-page and full-site
The difference between one-page tools and full-site tools is effectively the difference between taking a snapshot and fully crawling a site. One page web archiving tools will only capture the single page for the URL you give the tool. For example, if I want to archive the projects page of my personal website, I’d tell my tool to capture https://kam535.github.io/projects.html. If I wanted to archive the entire site, I would have to tell my tool to index the site or find the site’s sitemap for a list of every page on the site with the base url https://kam535.github.io/. The tool would then crawl the site and archive every page on that list.
The caveat is that a full-site software will almost always require a crawler. Crawler’s take physical and digital energy, and are often difficult to use if you’re unfamiliar with web archiving. For this reason, archiving of entire websites is usually only done by institutions, memory organizations, and other larger groups and polities. Institutions that require constant captures of full websites usually use a full-service software like ArchiveIt, which is managed by the Internet Archive. However, archiving an entire website is possible using a variety of tools that can group individually archived webpages into collections for easy access to the entire archived site. Depending on the size of the website, you can also simply archive each page of a website individually, and then access them all from a single tool or software.
Open source and closed source
Open source refers to software whose source code (the code that makes up and runs the software) is freely available and open to the public to access, modify, distribute, etc. Open source software is (almost always) free and can be remixed into other tools and software, tailored to an individual’s needs and use case, and shared with anyone you want. Open source software is often published under a specific Creative Commons license that stipulates what can be done with the software (for example, whether it can be modified and then sold commercially).
Closed source refers to software whose source code is owned and copyrighted by an individual, institution, or corporate entity and that cannot be freely shared with the public, modified for personal or commercial use, or distributed openly. Closed source software are black boxes; you can’t see the mechanisms that make them work, only what you put into them and what they spit out. Closed source software is usually paid, with tiers depending on what amount of storage and what features you need.
At the Digital CoLab, we highly prioritize the use of open source software for teaching, learning, and consultations, since we aim to contribute and help others contribute to the greatest possible human good.
Software and tool options
Michael Hucka, a Staff Software Engineer at Google, has compiled a gigantic web archiving software comparison list assessing a broad range of web archiving tools, both open-source and closed-source. Given that this list may be impenetrable to those new to web archiving, we have a few suggestions and recommendations for tools and software depending on your needs.
Note that because of the Digital CoLab’s values, all of the tools listed will be open-source (and thus free). Paying for web archiving software can be useful for institutions, but individuals should have access to high quality tools and software that can help them contribute to the public good without accruing a financial burden. Additionally, open-source tools invite innovation; developments and improvements to open-source software are common and encouraged, meaning that a useful plugin or even a better version of what you’re using may crop up in the future (and who knows, maybe even you could build one!).
Full-service software
Perma.cc
🌲 Conifer
The Wayback Machine
Self-managed
🍨 Scoop

ArchiveBox
With all of the above self-managed software, you can use your local server or a viewer like Replay Webpage to look at your WARC files.
Guide for using self-managed software
Step 1. Learn to use the command line
If you’d like to have a self-managed web archive, you will need to learn how to use your computer’s command line effectively. Almost all self-hosted web archiving software uses the command line, in part since this is where you’ll connect to your local server. Programming Historian has approachable lessons in English for using the Bash Command Line (MacOS) or PowerShell (Windows).
Step 2. Decide what software you want to use
Deciding what software you’d like to use can be difficult! Luckily, there are plenty of lists like this web archiving software comparison list and this awesome web archiving list, which will give you basic information about the features of each software or tool. If you don’t understand a term that’s used to describe a piece of software, make sure you look it up! The difference between a software that offers a CLI (command line interface) and a GUI (graphical user interface) could be the difference between having a usable tool and having an archive you don’t enjoy working with. Looking for something specific or not sure what you’re looking for? Feel free to reach out to the Digital CoLab for help.
Step 3. Read the software documentation
After you’ve learned to use the command line and have decided on a software, you’ll want to navigate to the documentation page for whichever software you decide to use. Documentation includes information for every step and feature of a piece of software. Good documentation should give you a list of dependencies, which are pieces of software or tools that you need to install on your computer before you can use the software. The best place to start in any piece of documentation is usually the Quickstart. Quickstart sections will give you a basic list of things to do to just get the software up and running, and then give you a list of things to do to get the software to do basic tasks (like capture a single webpage and save it into a folder).
For example, ArchiveBox’s documentation has a Quickstart section that guides you through three steps for getting started with archiving pages. You’ll want to make sure you’re following the steps that match your operating system (MacOS, Linux, Windows, etc.). If you’re not sure what your operating system is, you can find it in the system settings for your computer.
Step 4. Follow the documentation and start archiving!
Once you’ve followed the documentation, you should be all set up to start archiving pages! If you want to further control the methods of archiving, the output (snapshot, WARC file, etc.), and any other settings (such as setting up a browser-based interface to access your links), you should peruse the documentation for your software for more advanced guidance and information.
Step 5. (Optional) Learning proper file management
You may assume that self-hosted options or self-captured options are more stable, since they’re not living on someone else’s services, but the increased lack of literacy in basic file management indicates that this isn’t necessarily true. If you delete your WARC file or misplace it, your copy is gone.
File management is a skill dependent on understanding how your computer organizes files. One of the best ways to learn how to set up a file management system is to watch other people do it and try to find what works for you.
Some file management guides for Mac:
- Understanding the File And Folder Structure Of Your Mac by macmostvideo
- MacOS File and Folder Structure Tutorial – The Basics by Craig Neidel
Some file management guides for Windows:
- Windows 11 – Files & Folders for Beginners – Get Organized – Get Control of Your Files & Folders by Your Windows Guru
- Windows 10 – File Explorer Management Tutorial – How to Organize Files and Folders – Folder Manager by Professor Adam Morgan
- Note that Windows 11 has a Files app that is intended to optimize file management. See The File Explorer Replacement – The Files App for Windows! by Productive Tech.
Some file management guides for Linux:
- File Management in Linux by Peter Kay
You can find more guides on YouTube; just make sure that you’re searching for a guide that addresses your operating system and operating system version, since operating systems are updated somewhat regularly by Apple and Microsoft.
Step 6. (Optional) View your archive using an external viewer
Depending on what software you’re using, you may have to use an external viewer to look at your archived pages, especially if you have a folder full of WARC files. If your software produces HTML files, you should be able to open those files in any browser on your computer just by double clicking or right clicking the file and clicking “Open”.
The main browser-based viewer for WARC and WACZ files is Replay Webpage. Replay Webpage lets you upload WARC and WACZ files and view their contents in your browser. You can also install and use a replay tool like pywb, SolrWayback, or OpenWayback and use the command line to serve them to a browser.